
Deploying Stable Diffusion
前言
人工智能是当今科技领域最炙手可热的话题之一,它正在以惊人的速度改变我们的生活和工作方式。自 CHATGPT 问世以来,更多的人们看到了大模型人工智能的发展潜力,并以此为基础开发了大量的人工智能应用,包括但不限于文本生成、图像生成、问答式工具等等。
当这些人工智能模型被广泛熟知前我就有想法基于其做一些应用来尝试,但由于科研和工作的缘故一直没有开始这项计划,现在大量的人工智能模型已经被应用于现实并辅助我们完成各种任务,这也让我有信心去部署一些人工智能模型并应用到我想要实现的地方,仅以此文记录我模型部署、训练流程、参数调整和问题解决的过程。
具体的,我希望以现有的项目基础训练符合自己需求的生成式模型。
Stable Diffusion v2
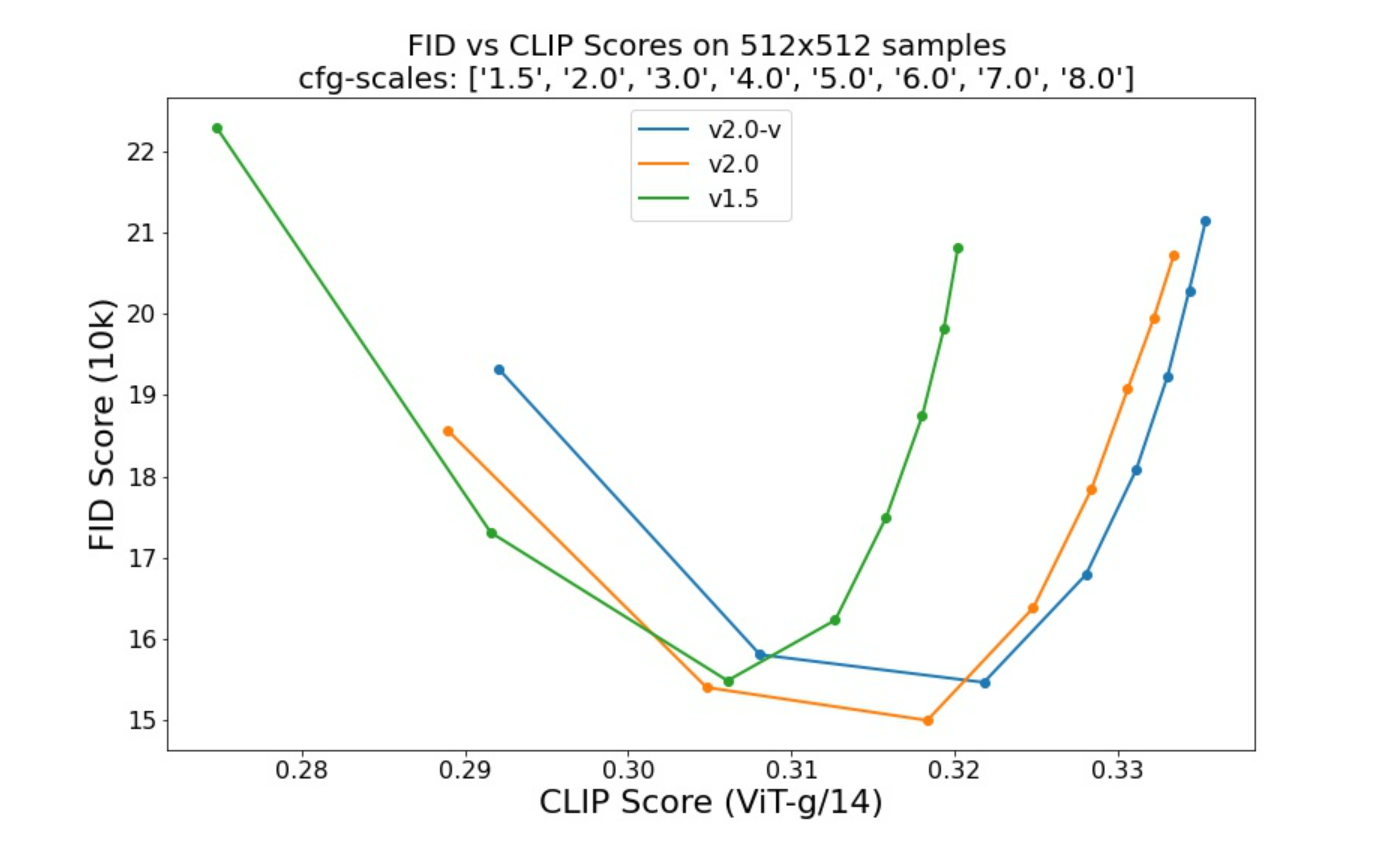
Stable Diffusion v2 是指模型的特定配置,使用下采样因子 8 自动编码器和 865M UNet 的架构以及用于扩散模型的 OpenCLIP ViT-H/14 文本编码器。SD 2-v 型号可产生 768x768 像素的输出。
使用不同的无分类器指导量表(1.5、2.0、3.0、4.0、 5.0、6.0、7.0、8.0) 和 50 DDIM 采样步骤显示了 checkpoint 的相对改进:
容器配置
我的主机是 Windows 系统,里面有很多的重要资源不能被破坏,因此我选择使用虚拟化技术完成模型的部署,即在 DOCKER DESKTOP 下运行容器部署。
首先我启动运行了 ubuntu 的最新版本镜像,在 DOCKER DESKTOP 中的名字为 StableDiffusionContainer,其容器id为 d6b2b7efcc2f75678de2d67dafdd317202b0d300c36f050e30e08aa76aea9a15。这是一个简易版本的 ubuntu 镜像,占用的空间少,带来的代价就是很多工具并没有安装,需要我们在使用的过程中自行解决。
我运行容器的指令为:docker run -itd --name ubuntuStableDiffusion --gpus all -v /E/_tmps/DockerContainers/ubuntuStableDiffusion:/root -p 8005:22 ubuntu /bin/bash
在 DOCKER DESKTOP 中直接使用命令行操作容器实在不便,terminal 界面的样式无法改变,因此通过ssh连接容器操作会更加方便。我们需要先用自带的 terminal 界面开启 ssh 服务,如此才能远程连接。
在 terminal 界面输入 /etc/init.d/ssh restart 用于重启 ssh 服务,然后输入/etc/init.d/ssh status 查看服务状态,显示 sshd service running 则代表我们成功开启 ssh 服务。
此时我们可以远程连接容器操作。
我在运行容器的时候将本机 8005 端口映射到了容器的 22 端口,因此我们通过 root 用户和 8005 端口连接此容器。
PS: 如果不想通过 ssh 连接容器,也可以直接在 terminal 里面执行,但是默认的 terminal 只显示井号(#)影响我们对于路径和配置的判断,需要切换到 bash 执行,使用 exec bash 指令,就可以显示出正常的 bash 提示词。
环境配置
配置容器环境的时候我们提到过使用的是建议版本的 ubuntu 镜像,很多功能需要我们在时候的时候自行配置,因此在进入容器后我们首先需要对基本环境进行更新。
输入apt-get upgrade 和 apt-get update等指令进行安装包的更新。
对于一些基本的环境如 git、gcc 和 g++ 等我们也需要提前进行安装。这里只展示部分需要安装的环境包,其余根据需求自行安装。
同时,由于我在运行容器的时候设置了 NVIDIA GPU 可见,所以我不需要在容器中配置 CUDA 等实验环境,而 Anaconda 的配置具体可以查看我之前的博客。
如果在安装 Anaconda 后无法使用 source ~/.bashrc 激活 Anaconda 环境,则需要先使用 conda init 指令来生成一个 .bashrc 配置文件。如果显示 conda: not found 则需要加入环境变量 export PATH=/home/anaconda3/bin:$PATH。
项目配置
下载 Stability-AI/stablediffusion 项目,使用 git 指令。

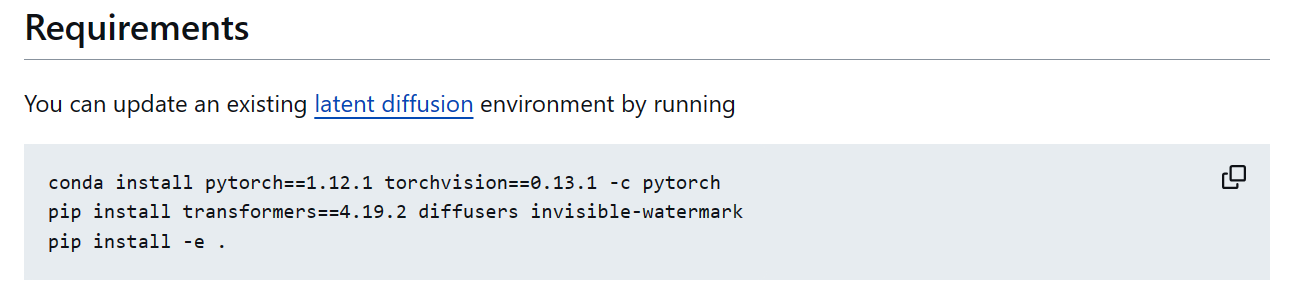
我们进入项目目录,根据官网提供的教程安装必备的 torch、torchvision、cudatookit 等相关的环境。
运行时需要一个预训练的模型权重,可以在官网提供的地址下载 SD2.1-v or SD2.1-base。
之后就可以使用指令 python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt checkpoints/512-base-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 512 --W 512 --steps 20 --device cuda 运行这个项目,我这里以文本生成图像为例子。
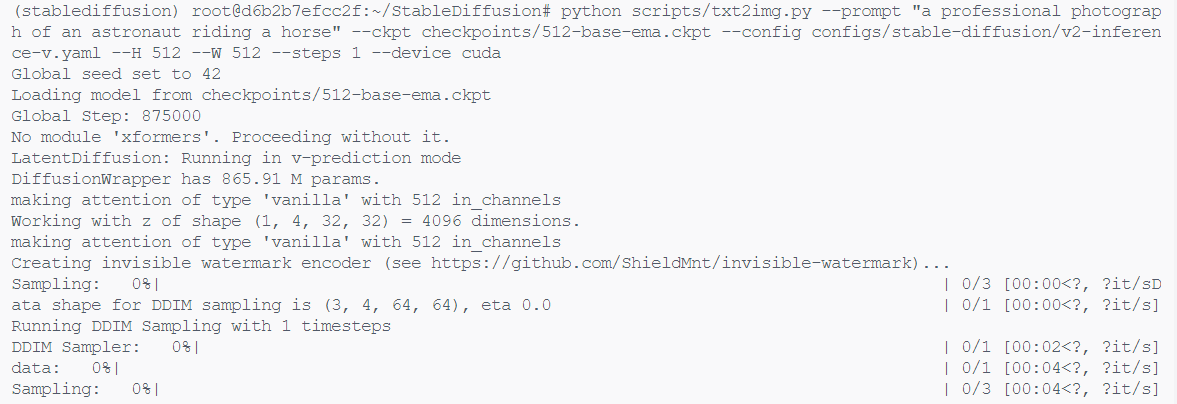
如果运行中遇到了下载文件失败的情况,可以选择先将文件下载下来本地运行或者是降低一些库的版本,具体可见下面的文章HTTPSConnectionPool(host=’huggingface.co’, port=443)错误的解决方法 。
至此就可以完成 Stable Diffusion v2 的模型部署,可以用于完成我们的任务。更多的任务在官网上可以看见,根据提示就可以实现,Stable Diffusion v2的gitee网址。
如有必要可以自己写一个前端用于可视化,这样会使得我们的操作更加直观。
后续就可以按照自己的方式训练模型,并将权重用于这个特定的任务,实现自己的”炼丹”之旅。
PS:很可惜,我的电脑使用的是 NVIDIA 3060 6G 的显卡,官方建议至少 8G 显存使用,因此我的机器无法运行 Stable Diffusion v2 的模型,降低显存消耗的方式我已经尝试过,其他优化的方法还没有尝试,就先到这里吧,等后续尝试一下其他方法或者是更换了更好的机器和显卡后再做尝试。

参考资料
ssh登录错误ECDSA host key for ip has changed解决方案
linux服务器下source: not found解决方法
libGL.so.1: cannot open shared object file: No such file or directory
HTTPSConnectionPool(host=’huggingface.co’, port=443)错误的解决方法
RuntimeError: expected scalar type BFloat16 but found Float #91